Lifecycle artifacts
Rollouts, reviews, datasets, training records, evaluations, and recollection plans remain linked across iterations.
Making policy iteration legible across data, training, evaluation, and recollection.
1Transcengram 2The University of Hong Kong 3Beijing Institute of Technology
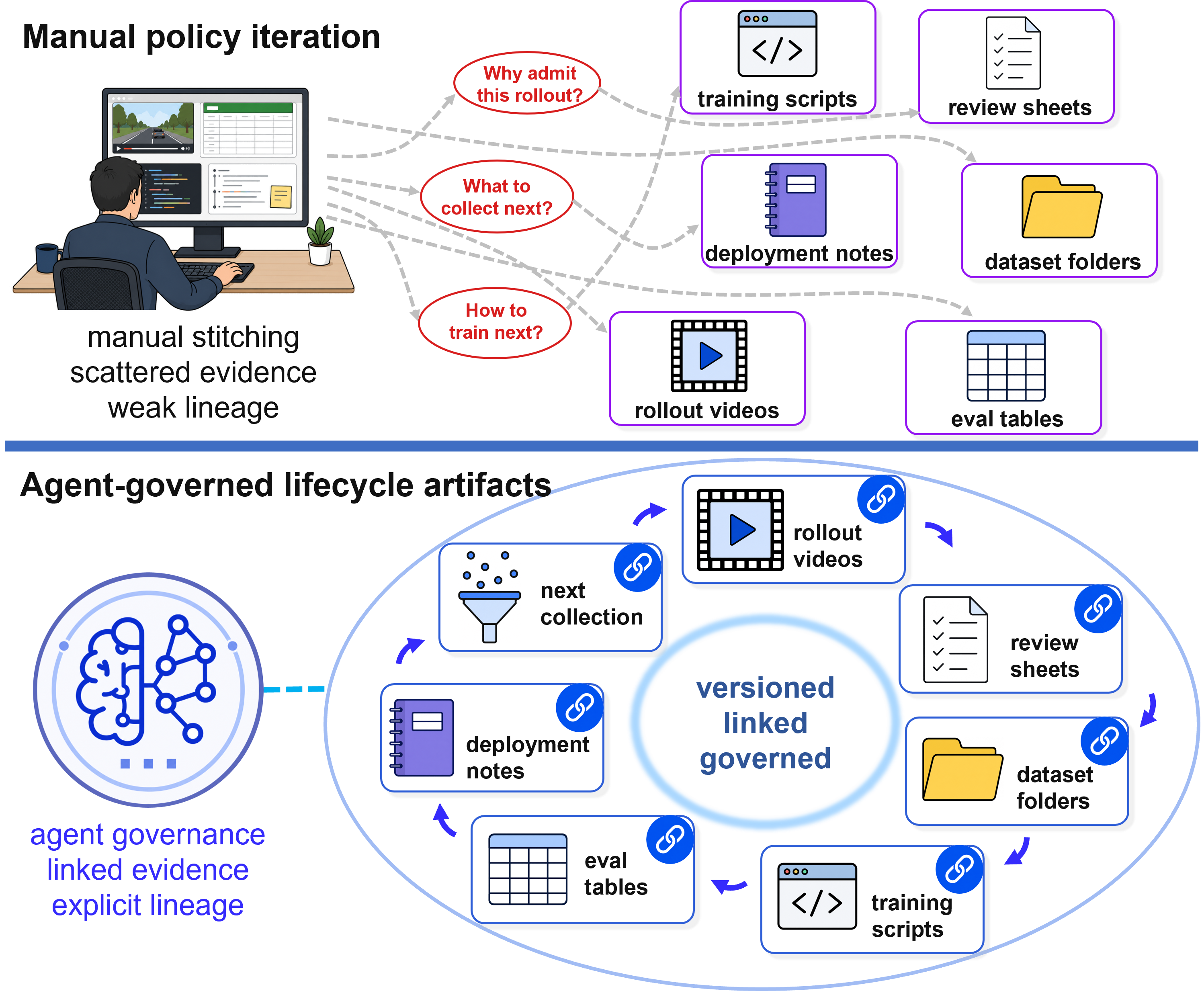

Existing robot policy iteration leaves much of the work between training runs to expert reconstruction: which evidence mattered, why data changed, and what should be collected next. RoboLineage turns those transitions into linked lifecycle artifacts that remain consistent as robots, data formats, and policy learners change. Across diverse real-robot workflows, this lifecycle reduces routine human effort while preserving policy quality.
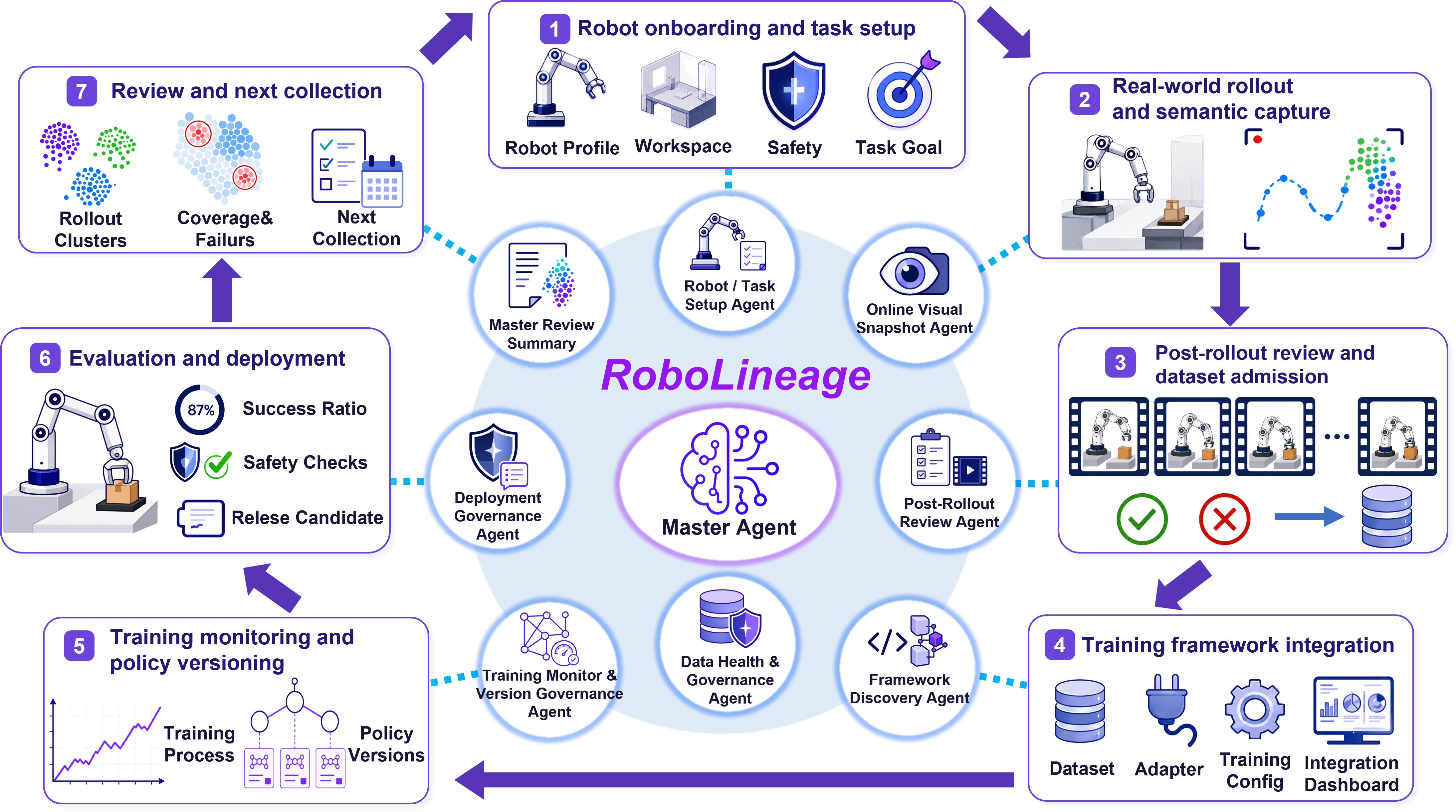
Modern robot policies improve through repeated data collection, review, retraining, evaluation, and release decisions, but the evidence connecting these steps is often scattered across local tools, scripts, and expert memory. RoboLineage makes this lifecycle explicit by representing rollouts, reviews, dataset decisions, training runs, policy metadata, evaluations, deployment recommendations, and next-collection plans as typed lineage artifacts.
Agents interpret embodied rollout evidence, adapt accepted data to existing training stacks, maintain data health, and summarize cross-iteration state under explicit artifact boundaries. In real-robot manipulation workflows, RoboLineage makes routine policy iteration faster and more auditable while maintaining downstream policy performance.
Rollouts, reviews, datasets, training records, evaluations, and recollection plans remain linked across iterations.
Agents prepare semantic evidence and summaries while validated artifacts carry lifecycle state.
The interface sits behind different robots and existing policy learners.
RoboLineage follows the policy iteration loop from robot onboarding and semantic capture to review, dataset admission, training integration, evaluation, and next collection.
Selected deployment clips span visual placement, transfer, tool use, sorting, wide-workspace manipulation, and contact-rich articulation.
Block placement.
Container transfer.
Contact-rich articulation.
Tool use.
Tennis-ball and golf-ball sorting.
Far-to-near transfer.
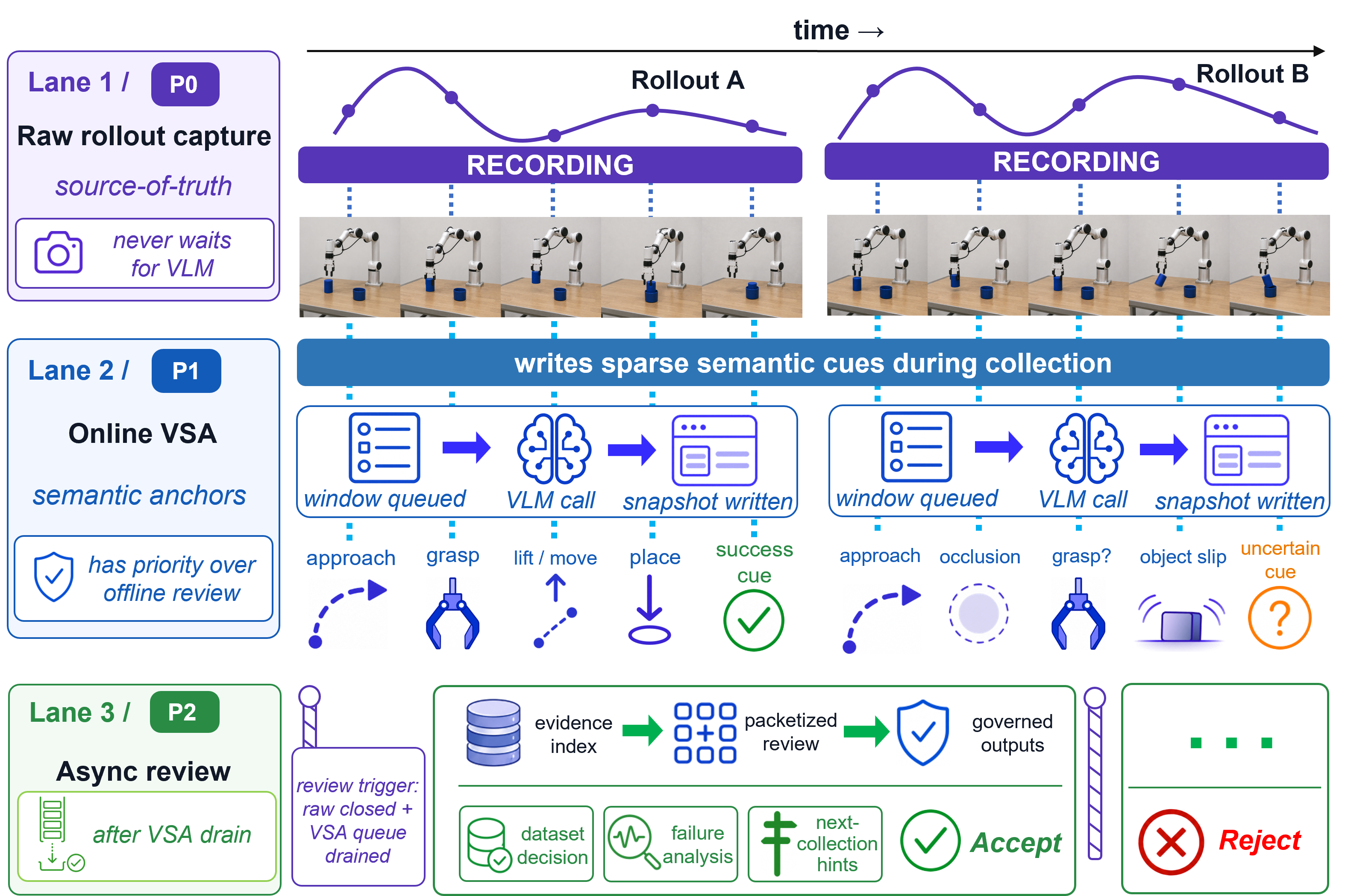
Raw capture remains the source of truth, online VSA writes sparse semantic anchors during collection, and asynchronous review turns evidence packets into dataset decisions and failure notes. The plates below show how task phase, outcome, uncertainty, and failure evidence are surfaced across representative tasks.
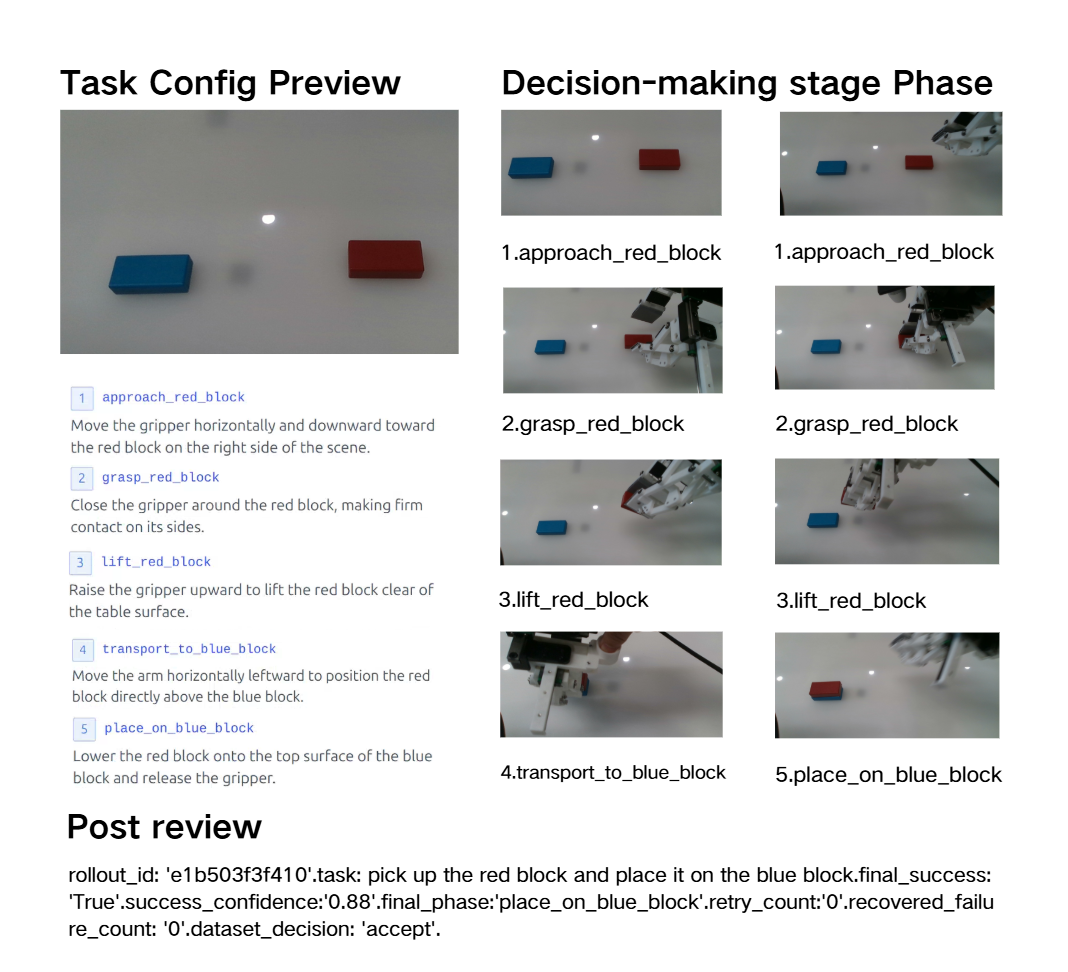
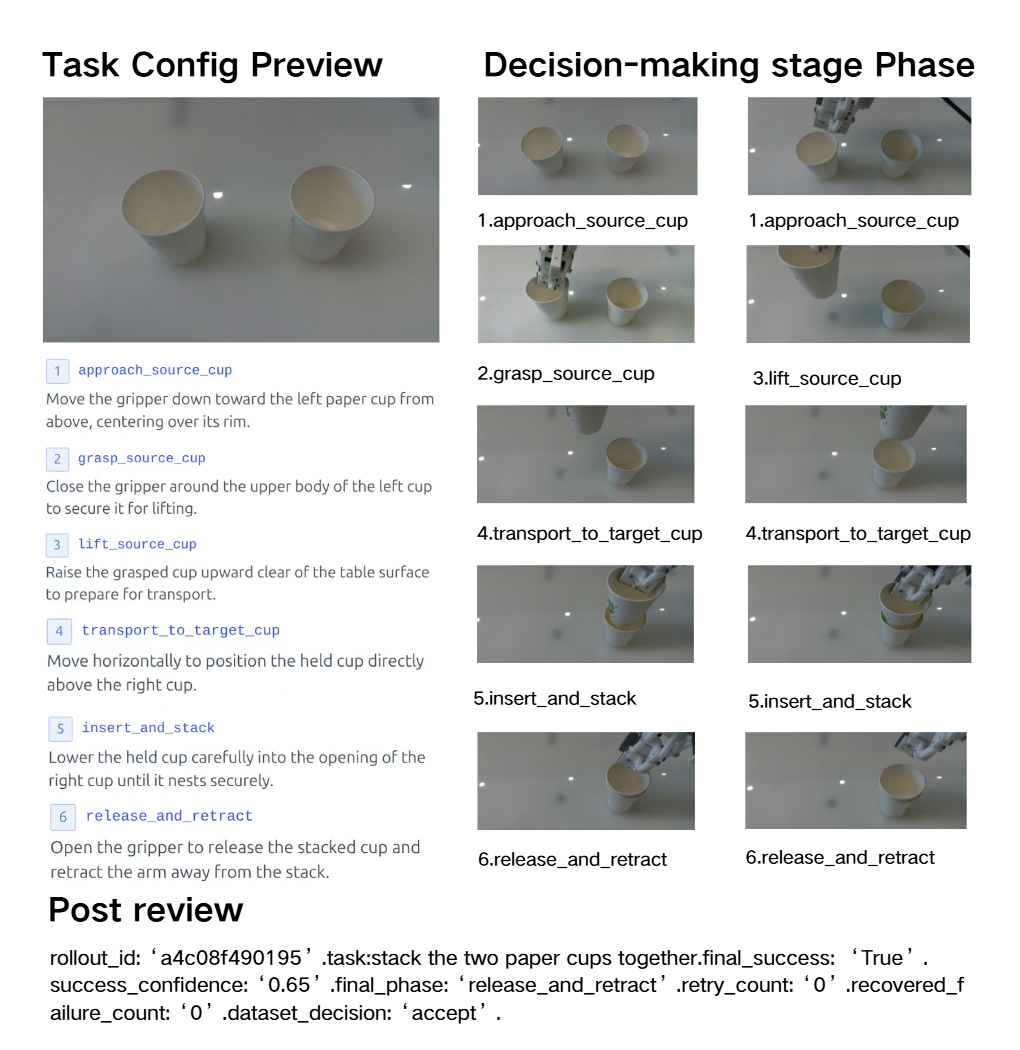

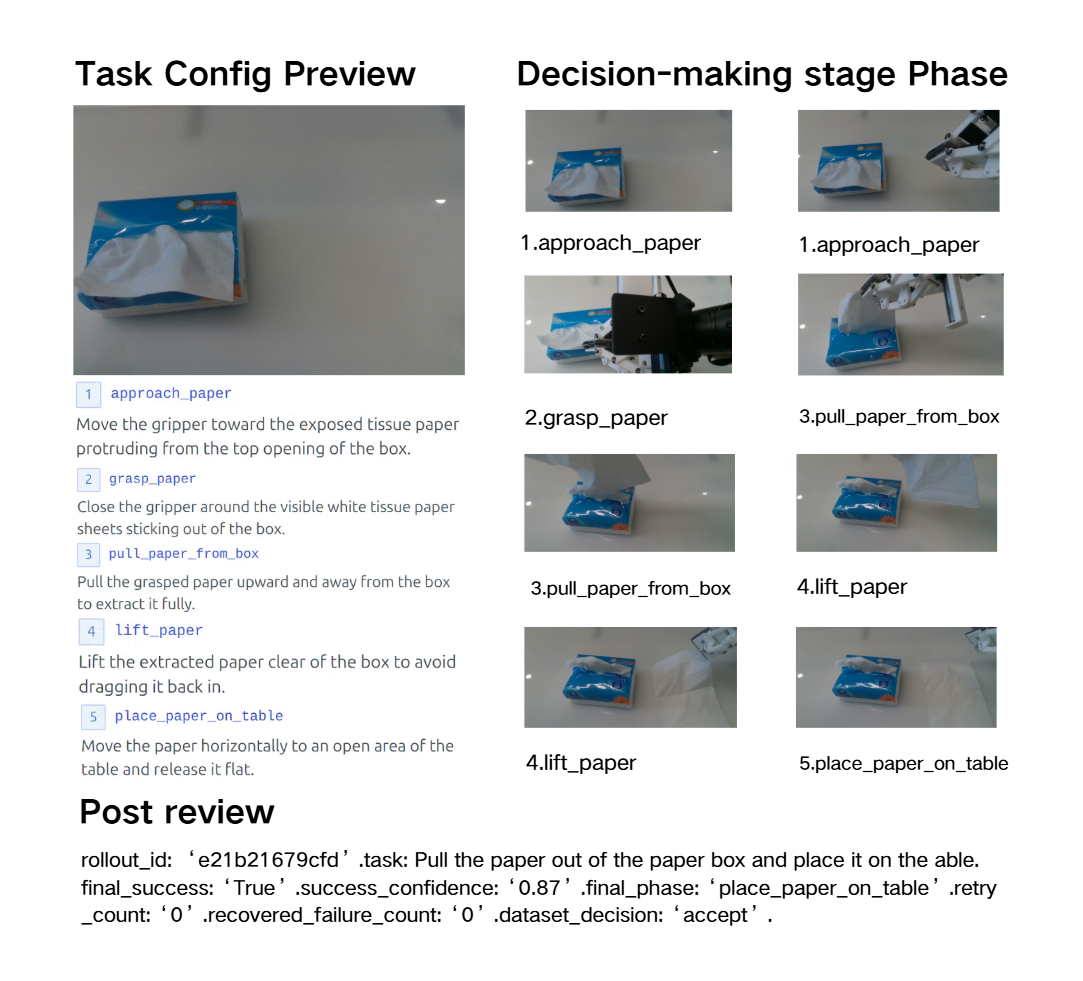

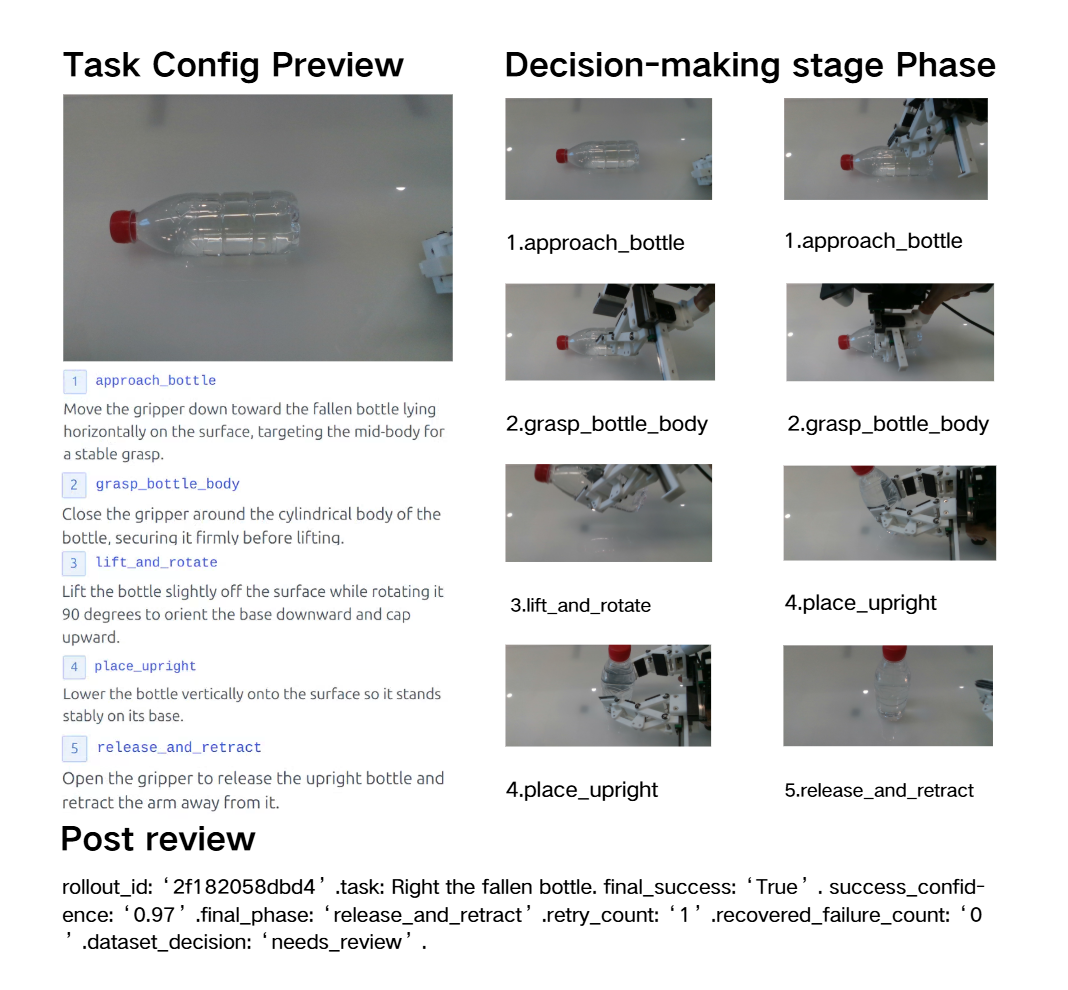
Failure analysis becomes data-collection action when review evidence is connected to dataset state, evaluation outcomes, and prior policy iterations. In the stacking case, repeated failures become targeted requests for out-of-distribution grasp locations, centered pre-release placement, and bounded-dwell release examples.

Read the preprint on arXiv:2606.22142.
@article{luo2026robolineage,
title = {RoboLineage: Agent-Native Data Lifecycle Governance Across Robot Policy Iterations},
author = {Luo, Qian and Guo, Wentao and Qin, Zhennan and Guo, Nanchun and Zhao, Yunhan and Ma, Yi and Yang, Yanchao},
journal = {arXiv preprint arXiv:2606.22142},
year = {2026}
}